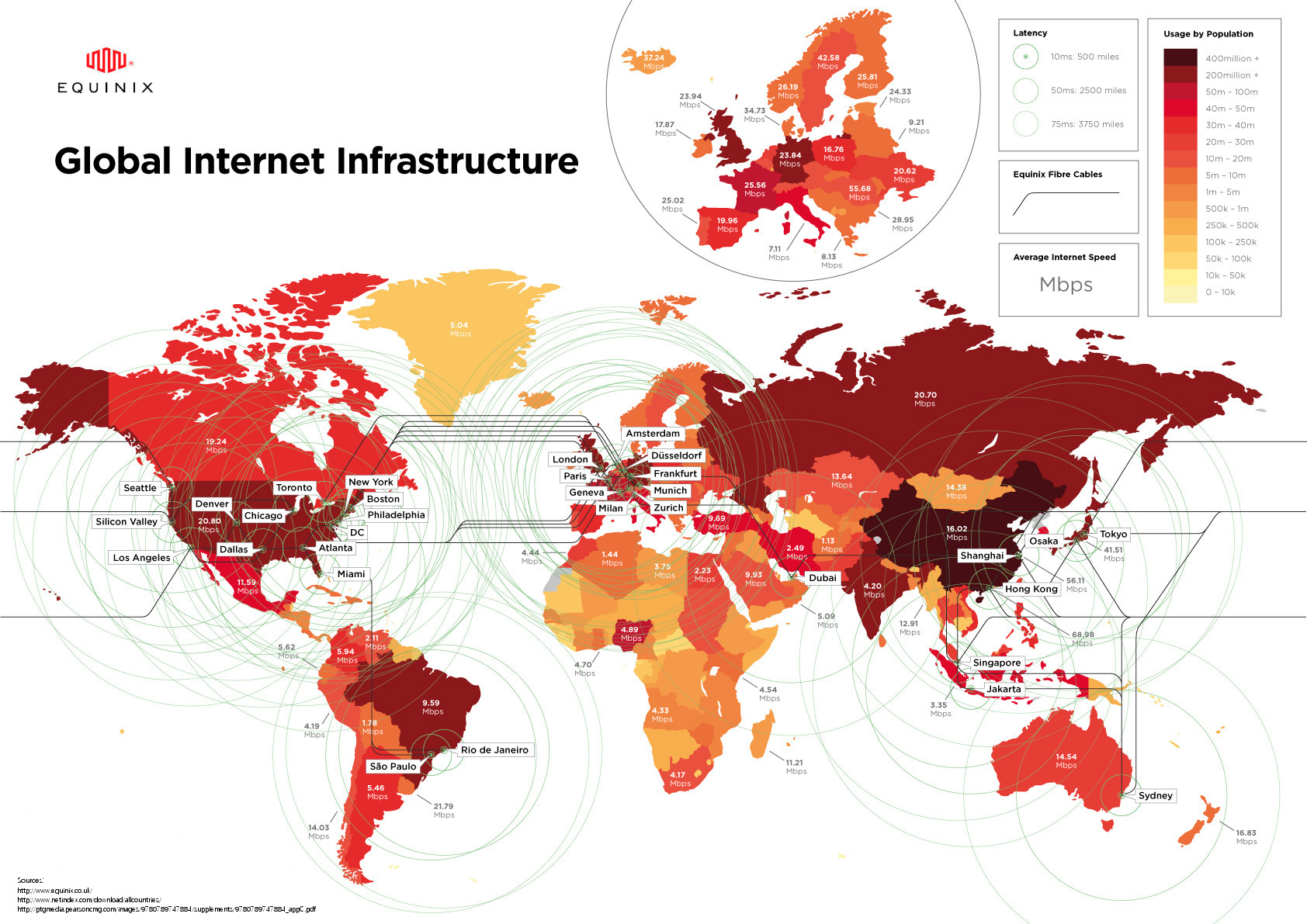
Latency is a time it takes for a bit of data to travel across the network from one node or endpoint to another before the receiver processes the information.
Latency Contributors
- Serialization delay
- Propagation delay
- Packet Switching
- Queueing
- Packet Drop
- Processing
What steps can be taken to reduce latency?
- Speed / Bandwidth – Bigger the network pipe lower will be the latency. Latency on a 1G network will be way higher than the 40G network. (Serialization delay)
- Media Type / Distance – Passive Twinax CX-1 (SFP+) cables are fastest when compared to Fiber Optic and Copper RJ-45 (CX-1 cable > 5m are consider active). Microwave are faster than Fiber Optic (Propagation delay)
- Switching mode – Cut-through provides deterministic latency, store and forward latency is lowest when the packet size is smaller. (Store and forward provide better latency number’s when the packet size is between 64 & 512). (Packet Switching)
- Buffer Amount – You need to consider buffer amount when you have speed mismatch on the network or you have many to once conversation. (Queueing & Packet Drops)
- Feature Set – Only enable required features to reduce latency. (Processing)
** N3548 has no latency impact regardless of features used
- Network Design – Spine and Leaf (Best for East / West Traffic) vs Traditional Hierarchical Architecture (Best for North / South Traffic)
- The Compute (Server Type) – Rack Servers are better than chassis base. CPU / Memory Type and Number. (Processing)
- The Adapter – Network Adapter with onboard CPU are faster. (Processing)
- Security – Hardware features (ACLs, PVLAN) and OS level security is better than firewall appliance from latency point of view. (Processing)
How to calculate Latency on different type of network devices.
Store & Forward Devices: The time interval starting when the last bit of the input frame reaches the input port and ending when the first bit of the output frame is seen on the output port.
Cut-Through Devices: The time interval starting when the end of the first bit of the input frame reaches the input port and ending when the start of the first bit of the output frame is seen on the output port.
Reference
BRKDCT-2214 – Ultra Low Latency Data Center Design – End-to-end design approach (Cisco Live)
RFC 1242, 2544, 2889, 391